
6 min
Agents Are Just State Machines: Rethinking Memory as an Immutable Event Log
Manveer Chawla
Updated on :

TL;DR
Most "agent hallucinations" in production are database problems: stale reads, race conditions, missing audit trails, broken referential integrity. The model didn't fail. The infrastructure did.
Make the agent stateless. Push durable state into a purpose-built memory layer. The model reasons. The database handles versioning, isolation, conflict detection, and durability.
The primitives needed are familiar database engineering: read isolation, MVCC, event sourcing, bitemporality, relational constraints, schema evolution, retention, provenance.
Vector indexes are search tools, not state stores. Framework checkpoints solve single-run replay, not cross-run audit. Postgres + pgvector gets you ACID and joins, but you assemble bitemporality, event sourcing, and retention yourself.
Pay for assembly, or pay a vendor to ship the assembly as a single system. Pretending it's a model problem isn't defensible.
A customer downgrades from 500 to 200 seats on a Wednesday morning. The support agent processes the change. Two hours later, the renewal agent reads a cached account snapshot and sends a 500-seat renewal at full price. The customer's VP of Engineering replies asking if anyone at the company talks to each other.
The model didn't hallucinate. It reasoned correctly. The infrastructure handed it a stale snapshot.
This is a database problem, not a model problem.
At Zenith, we've been building AI agents for two years. We've run an AI-native marketing agency on them for over a year, and shipped agents into other products across industries. I've watched this hit every deployment. Different customer, different agents, different industry. Every time, the team blames the model first.
Why teams misdiagnose agent failures
When agents fail in production, engineers tweak the prompt, drop the temperature, swap Claude for ChatGPT. Sometimes the model did confabulate. Most of the time it didn't.
Andrej Karpathy has called reliable agents a "decade project," with "reliable memory" and continuous action over time as the bottleneck. He's right about the timescale. Agent memory isn't a novel research problem, though much of the industry treats it as one. The failures teams blame on it are stale reads, race conditions, missing audit trails, and broken referential integrity. We've solved these before. A few teams are starting to apply that experience to the agentic stack, but the frame isn't widely recognized yet.
Agents should be stateless. Memory should be a database.
Web engineering made the same shift twenty years ago. Stateful application servers don't scale, don't fail gracefully, and don't compose. The fix: push session and durable state out of the app server, into databases (Postgres, MySQL) and session stores (Memcached, Redis). The app server became a stateless transition function. Read state, process, write state, forget. Scaling, failover, and concurrency stopped being application-layer hacks.
LLMs are stateless compute. A model call is a pure function from (system prompt + context + user input) to (output + tool calls). The model is good at state transition: reasoning, resolving ambiguity, and merging signals. It's bad at mechanical guarantees: versioning writes, enforcing referential integrity, providing consistent snapshots, detecting concurrent write conflicts, and managing retention. That's the database's job.
This is a separation of concerns, not a capability boundary.
The database detects conflicts. The model resolves them. When two agents write conflicting preferences for the same customer, the database catches it via optimistic locking, version checks, or serializable transactions. The model reasons about the resolution: re-read both inputs, weigh recency against authority, escalate to a human.
The database enforces structure. The model interprets meaning. The database enforces that an Order references a valid Customer. The model interprets whether the extracted "order" from a conversation is an order or a casual mention.
The database versions every state change as an immutable event. The model decides what's worth committing.
The database provides isolation. The model assumes consistency. If the snapshot is stale, the model's reasoning is correct, but its premises are wrong.
The agentic stack today treats the context window as both compute and state. The prompt is where the agent reasons and where its memory lives, stuffed with retrieval results, conversation history, system instructions, and cached fragments. The context window is the new $_SESSION: mutable, ephemeral, bounded, unversioned, unauditable, with no isolation between reads and writes. It works until you need a second server, a restart, a concurrent user, or an audit trail.
The vector database next to it is a search index, not a state store. Hamel Husain on naive RAG: "What's dead is the 2023 marketing version of RAG. Chuck documents into a vector database, do cosine similarity, call it a day. This approach fails because compressing entire documents into single vectors loses critical information." Husain's critique is about retrieval. The write path has parallel problems. A vector store optimized for similarity search doesn't give you typed entities with enforced relationships, versioned writes, transactional read isolation, multi-writer concurrency control, or retention semantics.
The same shift, mapped:
Web (2005 → 2015) | Agents (2024 → 2026) |
Stateful app servers (session in memory) | Stateful context windows (memory in prompt) |
| Conversation history, retrieval-stuffed prompts, LRU caches in app code |
The fix: stateless servers + relational DB + session store | The fix: stateless agents + purpose-built memory/context DB |
PostgreSQL, MySQL, Redis, Memcached | HydraDB, Postgres + event sourcing, XTDB, custom assembly |
Scaling = add servers, DB handles consistency | Scaling = add agents, memory layer handles consistency |
Failover = any server picks up from DB state | Failover = any agent picks up from committed memory state |
Session store with TTL, GC, eviction | Memory layer with retention, GC, temporal partitioning |
DB detects constraint violations; app logic resolves | DB detects write conflicts; model reasons about resolution |
Make the agent a stateless transition function. Make the memory layer a database.
Before each step, the agent reads relevant state with explicit isolation semantics (snapshot, read-committed, or stronger). The database guarantees consistency. The model trusts it. The agent reasons. The model produces outputs, decisions, tool calls. After each step, the agent writes resulting changes back as immutable events. The database handles versioning, conflict detection, durability. If a write conflicts with a concurrent write, the database surfaces it. The model or a human resolves it.
Between steps, between sessions, between agents, the database is the source of truth. No agent holds state. Any agent picks up any workflow from the last committed state.
The analogy isn't perfect. Web requests are short and don't reason about their own history. Agent workflows are multi-step and reason about what they believed three steps ago. The memory layer needs more than a session store: temporal queries, event sourcing, and context graphs to carry structured state across sessions.
Four agent failure modes (only one is the model)
Most production "agent failures" get lumped together as hallucinations. They aren't. There are four failure classes. Only one lives in the model.
Model confabulation. The LLM invents facts not present in any context. Memory architecture can't fix it. The fix lives in the model layer: better grounding, structured output, retrieval before generation, evals.
Stale-context reads. The agent acts on memory another process has since invalidated, or on a snapshot assembled from cached fragments without transactional coherence. The agent equivalent of a stale read or read skew. The opening incident: the renewal agent read a 500-seat snapshot two hours after the support agent committed the downgrade.
State-continuity failure. The agent's durable session state is missing, partially checkpointed, or interpreted under a changed schema between turns. Restart-and-lose-context, or schema-migration-broke-replay. A durability and schema-evolution problem.
Cross-agent corruption. Two agents writing the same shared state without coordination, with the system silently accepting last-write-wins. A concurrency-control problem.
The four get conflated as "the AI hallucinated again" because the surface symptom is the same: the agent confidently outputs something wrong. The root causes are different. Three of them (2, 3, 4) are infrastructure problems commonly manifesting as the State Confusion Problem.
The infrastructure primitives that address those failures are read isolation, concurrency control, event sourcing, bitemporality, relational constraint enforcement, schema evolution, retention, and provenance.
Stale reads vs. dirty reads in agent memory
One agent commits a change. Another reads a cached snapshot from before the commit and acts on outdated state. That's a stale read.
Tacnode argues that stale context is the root cause of a class of agent failures usually blamed on the model: "Wheel-spin isn't a model problem. It's an infrastructure problem."
This isn't a dirty read. A dirty read means reading data written by a concurrent uncommitted transaction. A stale read in agent memory is reading old committed state, or a snapshot assembled from cached fragments with no shared transactional boundary. Closer to a stale read, read skew, or a non-repeatable read. The precision matters: the fix differs.
Production agents need at minimum read-committed semantics. Snapshot or stronger is better. Prompt context windows have undefined isolation. The prompt is assembled from a vector retrieval, a Redis cache lookup, a session JSON blob, and a tool output, with no transactional coordination. Whatever the agent reads is whatever each subsystem happened to return.
Vector databases have eventual consistency. Writes propagate to indexes asynchronously, with documented lag windows. That's a known shape, not a one-off bug. It's fine for retrieval-augmented generation over a static corpus. It's not fine for an agent reading and writing to the same store. The agent needs at least a consistent snapshot of committed writes, ordered against a known transaction-time horizon. Most agent memory implementations weren't built to give that guarantee.
The fix is to give the agent a defined isolation level when it reads. Isolation level is a property of a single transactional system, not a federation of stores stitched at the application layer (vector DB + cache + JSON blob).
Multi-agent write conflicts: the database detects, the model resolves
Two agents read the same record at the same time. Both write. Under last-write-wins (the default in most agent memory implementations), one intent silently disappears. The audit log shows the survivor. No trace of the conflict.
This isn't theoretical. Tian Pan documented the failure mode in production: "Three agents processed a customer account update concurrently. All three logged success. The final database state was wrong in three different ways simultaneously... The team spent two weeks blaming the model. It wasn't the model. It was a race condition." A LangGraph practitioner running five Claude Code agents on the same repo: "about 24% of intended changes disappeared while the build still passed, and one agent's auth routes were completely lost." The surface symptom looks correct: a passing build, a database that reads back consistently. The error is in what's missing, not what's wrong.
Most agent frameworks solve multi-agent coordination via queue-based orchestration (Temporal, Inngest), turn-taking protocols, or last-write-wins acceptance. Not via database concurrency primitives. Queues aren't wrong. They're a reasonable answer for some workflows. But the agent state layer should give you the option of database-grade conflict detection when you need it, not force you to build coordination outside the data layer.
Under MVCC plus expected-version checks, or under serializable transactions where the conflict is expressible to the database, the second writer's commit is rejected. The database surfaces both intents in the audit log. The model decides which wins, weighing source authority, recency, and specificity, or escalates to a human. A model is well-suited to that judgment. It can't make it if the infrastructure silently swallowed the conflict.
MVCC alone gives you snapshot reads. It doesn't detect every semantic conflict at the application level. Conflict detection requires explicit optimistic concurrency control: expected-version checks, compare-and-swap, serializable isolation, or stream-version checks. That layer needs to exist, exposed to the agent, with semantics that the agent or a human can reason about.
Event sourcing vs. checkpointing for agent state
A customer disputes an outcome that an agent committed months ago. A regulator asks how a decision was made. An internal review needs to understand why the agent acted on stale data. The team has to reconstruct what the agent read, what was said in the conversation, what the agent committed, and what downstream systems consumed the commitment. If memory only stores the current state, there is no trail for proper decision traceability and auditability.
Aaron Cheiffetz at Finextra frames it as the audit-trail problem: conventional logs are "telemetry, not testimony." They capture what an agent did, not why.
At Zenith, we run this audit pattern often. When customers flag content that's gone stale, we need to know whether the agent had the right source documentation at decision time, or whether something else caused the mis-grounding. Without an immutable trail, the answer is a guess.
LangGraph, CrewAI, and AutoGen ship state checkpointing. LangGraph's persistence layer saves graph state as snapshots and supports time-travel by replaying from a checkpoint. CrewAI persists workflow state to SQLite or vector stores.
Event sourcing is the broader primitive. The argument is structural, not stylistic. Checkpointing answers "redo this run from step N." It captures one moment in one run. Event sourcing answers four things checkpointing alone does not.
First, queries that span multiple agent runs and sessions. Such a dispute spans months, multiple agents, and downstream systems. No single LangGraph checkpoint covers it. An event log scoped to the affected entity does.
Second, disciplined schema evolution. Events are immutable. Readers tolerate version envelopes. Old events project into the new schema via upcasters. Event sourcing gives you a path, not a free lunch. This is how you keep historical records interpretable when the customer model changes. Snapshots don't. When the snapshot schema changes, the old snapshots are dead weight or require migration.
Third, rebuilding derived views without reprocessing every agent execution. Per-customer summaries, per-tenant aggregates, per-tool usage analytics: all are projections over the event stream. New view, new projection. Not a new run of every historical agent.
Fourth, cross-agent and cross-session audit trails. Reconstructing the dispute requires tracing a decision across multiple agents and downstream systems. Framework checkpoints are scoped to a workflow run. Event logs are scoped to the entity. The disputed entity's history spans every agent and system that touched it.
For single-agent, single-session workflows, framework checkpoints are a reasonable lighter-weight choice. For anything that touches the same entity across runs (which is most production agent work), event sourcing is the broader primitive. Checkpointing is a special case. Tian Pan: "Agent state as event stream" scales with cross-run, cross-agent reasoning.
Bitemporality: system time vs. valid time
An agent acts on a fact. Later, the fact changes, or gets retroactively corrected. Two questions arise. What did the agent see when it acted? And what was actually true at that moment?
These are different questions. The first is system time: the value the database held when the agent read it. The second is valid time: the value that was true in the world. Without bitemporality, you can't answer either cleanly. You replay logs by hand and hope nothing was overwritten.
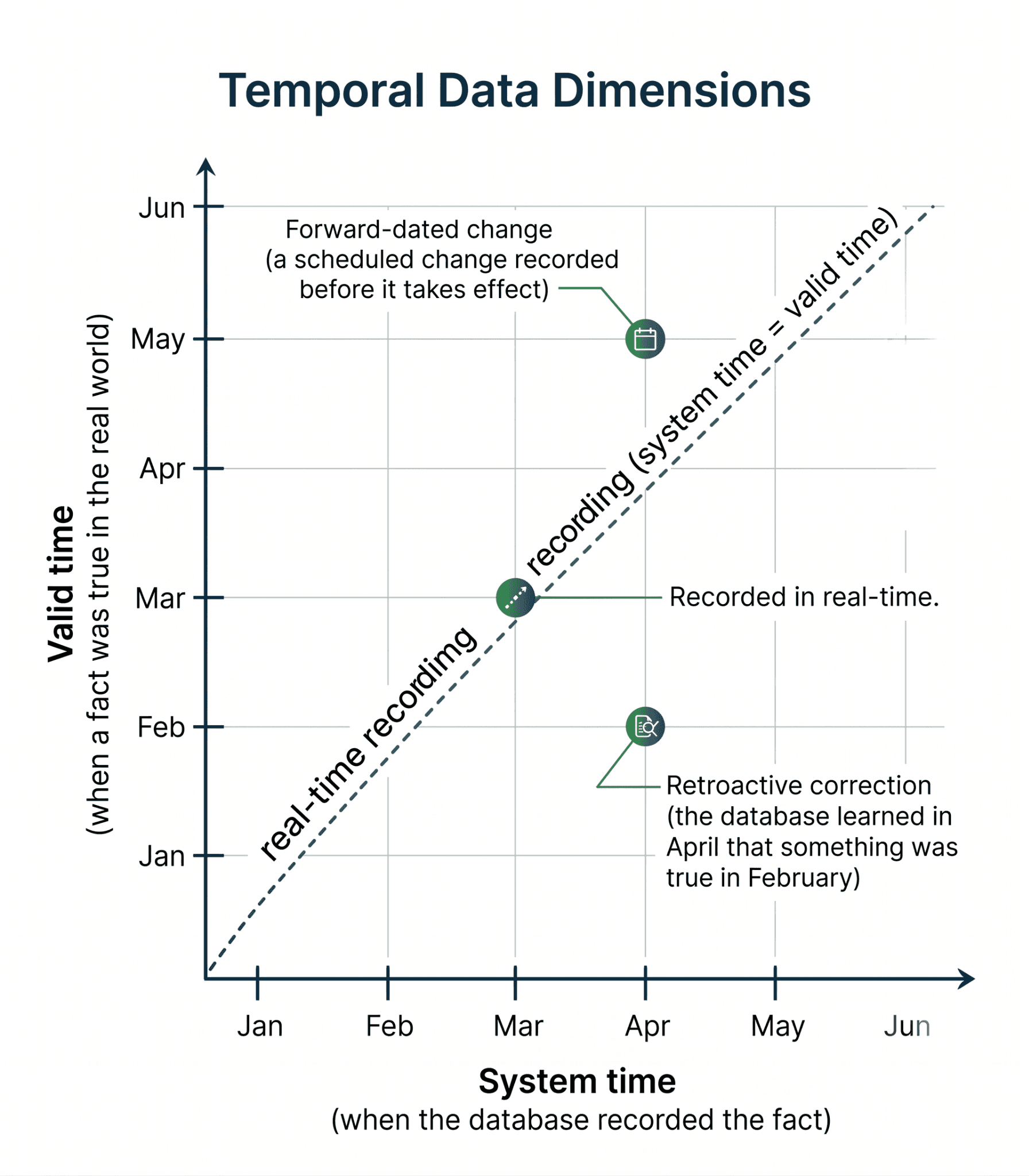
The pattern is well-established in regulated industries. In financial trading, trades get amended after the fact, and without bitemporal records of those amendments, firms face regulator fines. The standard examples (backdated insurance policies, invoice corrections, retroactive HR changes) all need the same primitive.
At Zenith we run agents that watch product documentation and update derived customer content when the source changes. When the system slips, the post-mortem needs both axes: when our knowledge base recorded the change versus when it actually happened in the world. The gap tells us whether we were late or whether the content was wrong from the start.
That distinction separates agents that support auditable replay, root-cause debugging, and post-hoc correctness checks from black-box stateful blobs. Most agent-memory work doesn't draw it.
Bitemporal databases go back to Snodgrass in the early 1990s. Datomic productionized transaction-time history with as-of, since, and history filters. XTDB v2 went further: "Unlike other SQL databases, XTDB tracks both 'system time' and 'valid time' automatically... All tables are bitemporal tables." Queries like SELECT * FROM customers FOR VALID_TIME AS OF '2026-03-12' are a single SQL statement, not a custom event-log replay scaffold built in app code. An immutable temporal substrate gives you "history that cannot lie, queries that cannot race, and a model you can reason about in daylight". An agent memory layer worth auditing needs the same.
Postgres can do this with discipline: temporal_tables for system-period support, application-maintained valid time, careful trigger plumbing. Bitemporality isn't exotic. Any production agent making decisions worth auditing needs both axes. Most teams are still assembling them by hand on stores that don't expose them natively.
Relational integrity, not vector metadata filters
An Order must reference a valid Customer. A Renewal must link to an existing Contract. A Discount must apply to a specific tier. These are constraints. The database enforces them at write time. A vector index can't.
Vector databases aren't untyped blob stores. Pinecone supports metadata filtering. Weaviate has schema definitions and cross-references. Qdrant has typed payload indexes. The mechanism exists. It isn't relational integrity.
When an agent pulls a contract and the linked seat-count and tier records, a vector-only layer can't guarantee those records are from the same coherent state. Two records that match a query by similarity have no enforced relationship to each other. The agent gets an inconsistent profile and reasons over it confidently. This lack of state management causes context rot, highlighting why autonomous agents require a dedicated agent memory layer instead of a stateless vector database.
No foreign keys across entity boundaries. No referential integrity enforced on write. No schema migrations with constraint validation. No transactional invariants spanning multiple records. A Weaviate forum thread, "Messing up search results under parallel write operations," reports results that don't reflect concurrent updates. The fix isn't "add more retrieval." It's a typed entity graph with enforced constraints.
Schema evolution and retention in event-sourced memory
A schema upgrade hits months into production. "Contact preference" splits into "support" and "billing" channels. A new "churn risk score" field is added. Product wants to query historical data with the new shape. Events from before the upgrade don't have churn risk scores. They have one "contact preference" field, not two. If events are immutable with versioned envelopes and tolerant readers (or upcasters), old events project into the new schema on read. If the team ran a destructive migration, the original context is lost and the projection is a guess.
This is event-sourcing 101 applied to agent belief schemas. Greg Young and Vaughn Vernon have been writing about event versioning for over a decade. The patterns (version envelopes, weak schema, upcasters, copy-and-replace) are well established. They require discipline up front. Most agent memory implementations don't commit to it because they were built around current-state representations, not append-only event logs.
Retention is the other side of immutability. Different parts of an agent system have different retention requirements. A data processing agreement requires deleting conversation transcripts after 12 months. Compliance keeps reasoning traces for 7 years. Quality monitoring retains embeddings for 30 days. Can the memory layer express "keep the event log, compact the embeddings, crypto-shred the transcripts" without a manual migration?
Immutability is the substrate, but legal deletion and tenant isolation cut across it. For GDPR, EventStoreDB requires destructive "scavenge" operations that permanently remove deleted or expired events from the global stream. Datomic uses excision. Postgres-backed event stores typically use crypto-shredding: encrypt PII fields with per-record keys, then delete the key when the record must be erased. Postgres also gives you VACUUM, MVCC visibility horizons, partition-based retention, and TTL extensions. Agent memory layers need analogous primitives: temporal partitioning, retention policies for different data classes, a vacuum equivalent that reclaims space without breaking replay, and crypto-shredding for fields that can't remain even in compacted history.
The tension is well-documented in event-sourcing literature. Most agent memory implementations have none of the primitives. They're running on borrowed time before the storage bill, the latency profile, or the first compliance audit forces a rewrite.
Provenance and auditability in agent memory
Database primitives ensure state correctness: what was true, when, and how it changed. Epistemic correctness is a separate concern: why an assertion is true. Agent memory isn't just facts. It's assertions, evidence, confidence, source, extraction method, and revision history. A typed graph can enforce that an Order references a valid Customer. It can't enforce that the extracted "order" from a conversation is an order rather than a casual mention. A database enforces structure, not reality.
Every assertion should carry provenance: the source utterance, the extraction model and version, the confidence, the valid-time claim, and a link to the prior assertion it supersedes. A versioned belief ledger over evidence, not a fact store. When a customer says "switch billing contact to the IT admin," the stored assertion is the customer's stated billing-contact preference at that conversation turn, linked to the turn itself. Later updates create new assertions linked to their sources, not destructive overwrites.
This changes what the agent can do. Reason about its own beliefs. Distinguish high-confidence facts from low-confidence inferences. Audit decisions back to evidence. It also changes what the system can claim about its outputs. The database stores provenance. The model uses it to reason.
Simon Willison's "lethal trifecta" (private data + untrusted content + external action) makes auditability the floor for any agent system handling production data. Provenance is how you reach that floor. A graph without provenance is a belief ledger you can't audit.
Four agent memory architectures compared
Architecture | Examples | ACID + Isolation | Bitemporality | Multi-writer concurrency | Audit / Event sourcing | Best for |
Vector indexes | Pinecone, Weaviate, Qdrant, Milvus | Eventual consistency | None | None | Limited | RAG with stateless agents |
Postgres + pgvector | — | Native | Assemble (temporal_tables) | Native (Postgres MVCC) | Assemble | Teams with DB engineering bandwidth |
Framework checkpointing | LangGraph, CrewAI, AutoGen, LlamaIndex | Inherits backing store | Single-run only | Queue-based or last-write-wins | Per-run snapshots | Single-agent workflows |
Purpose-built memory | HydraDB, Mem0, Zep, Letta, Cognee, Graphiti | Mostly not exposed | Both axes in leaders (HydraDB, Zep). | Versioned edges in HydraDB; varies elsewhere | Append-only graphs | Multi-agent, cross-run state |
Dedicated vector indexes (Pinecone, Weaviate, Qdrant, Milvus) solve similarity search well. They have schema definitions, cross-references, typed payload indexes, metadata filtering. They don't provide relational integrity across entity boundaries, multi-entity transactional invariants, bitemporal queries, or multi-writer concurrency control. Acceptable for retrieval-augmented generation with stateless agents. Unsuitable as the canonical store for stateful agents.
Postgres + pgvector is a credible canonical store. It inherits Postgres ACID, joins, foreign keys, point-in-time recovery, and schema migrations. The right starting point if your team has database engineering bandwidth. The tradeoff: you're assembling bitemporality, event sourcing, graph projections, retention, and agent-specific ergonomics yourself, on a stack where schema migrations cross engines and transaction boundaries split across stores. The pieces exist. The integration cost is months of senior engineering, and the seams break under production load. Bitemporal correctness becomes your team's problem to maintain.
Agent framework checkpointing (LangGraph, CrewAI, AutoGen, LlamaIndex Workflows) solves replay within a single run. Persistence layers serialize graph state to SQLite, Postgres, or Redis. Doesn't solve cross-run bitemporal queries, multi-agent concurrency on shared entities, or schema evolution across belief versions. Acceptable for single-agent or queue-orchestrated workflows. The right complement to a database, not a replacement.
Purpose-built agent-memory systems (Mem0, Zep, Letta, Cognee, Graphiti, HydraDB) are an emerging category. As teams evaluate Mem0 and Zep alternatives for production, it becomes clear that each makes a different bet:
Mem0: token-efficient memory with single-pass ADD-only extraction. Optimized for cost and throughput, with less emphasis on long-context coherence. Not pitched as a transactional system.
Zep / Graphiti: temporal context graph with
valid_atandinvalid_atmarkers, sub-200ms retrieval. Bitemporal-leaning, without explicit ACID/MVCC claims.Letta (formerly MemGPT): memory managed by the LLM in an "OS paradigm." Innovative on agent ergonomics, less aligned with database-grade semantics.
Cognee: knowledge engine combining graphs and vectors. Less emphasis on bitemporality.
HydraDB: append-only temporal graph with versioned edges (writes preserved with system and event timestamps), automatic graph extraction without manual schema, Sliding Window Inference Pipeline for chunk enrichment, shared cross-agent memory ("Hive Memories"). Read/write paths isolated; ACID-style isolation levels and commit-time MVCC on the roadmap.
Each addresses a piece of the agent-memory shape. None, including HydraDB, exposes the full set of database-grade primitives: ACID transaction guarantees, explicit isolation levels, full Snodgrass-style bitemporality (system time + valid time as queryable dimensions), MVCC with optimistic concurrency control surfaced to the agent, and disciplined schema-evolution tooling.
A vector DB isn't enough. A general-purpose OLTP database isn't enough either. It gets you ACID and relational integrity, but you assemble the rest. Furthermore, forcing B-tree metadata filtering, vector search, and graph traversal into a single query path creates a storage-layer crisis that degrades performance. Every team running a stateful agent in production is paying for the missing pieces somewhere: in glue code, in query latency, in audit gaps, in rewrites. Pay for assembly, or pay a vendor to ship the assembly as a single system.
When agents don't need a memory database
Not every agent needs database-grade memory. An agent that runs once, doesn't share state, and doesn't write back to anything external can get away with a vector index and a session blob. A conversational agent with no consequential actions outside the chat doesn't need durable, audited, coordinated state. A coding agent running on one developer's machine has no multi-agent concurrency to worry about. A research-summary agent whose value is the output, not the persisted facts, doesn't need a belief ledger.
The frame matters when an agent is stateful, multi-step, and shares state with other agents or systems. That's most production agent work. It isn't all of it.
Where HydraDB fits
HydraDB sits in the purpose-built lane. It ships a Git-style append-only temporal graph, automatic entity and relationship extraction without manual schema definition, a Sliding Window Inference Pipeline that makes chunks self-contained before retrieval by resolving entity references and embedding contextual bridges, multi-tenant and sub-tenant isolation, metadata-filtered and graph-enriched recall, recency-biased search, and shared cross-agent memory through Hive Memories. The temporal graph is real append-only history, not destructive overwrites: the substrate the event-sourcing reframe demands. Concurrent writes between two entities are preserved as separate versioned edges with system-time and event-time metadata, not silently overwritten. Read and write paths are explicitly isolated, so heavy ingestion doesn't degrade read latency. Each edge carries reasoning context, sentiment, and situational factors as metadata, encoding the "why" of every state transition. The graph extraction provides relational context at retrieval time (entity paths, relationship types, temporal signals) that vector-only stores don't.
In production, HydraDB sustains 2.5 million tokens per minute of ingestion with sub-500ms wait times at peak, and has handled bursts of 50 million tokens per hour under noisy-neighbor conditions. The write side is what makes a memory layer viable as a canonical store, not just a retrieval cache.
The architectural choices show up in benchmarks. On LongMemEval-s, the long-context conversational memory test (500 question-conversation stacks, 115k tokens average per stack), HydraDB scores 90.79% overall: state of the art by +5 points over the next-best purpose-built system, with 100% on single-session recall and 90.97% on temporal reasoning.
The edge model captures both transaction time and valid time per relationship. A SQL-like queryable interface for these axes (like XTDB's FOR VALID_TIME AS OF) isn't shown in public docs. The graph gives relational context at read time but doesn't enforce relational constraints at write time. Compliance covers RBAC, SSO, audit logs, and encryption, not first-party SOC 2 or GDPR attestations. Deployment options include managed cloud and BYOC: a HydraDB cluster running inside the customer's AWS VPC, with observability, CI/CD, and scale-to-zero baked in.
HydraDB's roadmap targets several of these layers directly: weighted nodes for graph-level reasoning, state-space-model architectures for more efficient memory tracking, orchestration harnesses for switching between file-system memory and long-term memory, file-system memory APIs for cloud-native deployments, end-to-end observability into ingestion processing, and a production version of the Bio-Mimetic Decay Engine for retention.
I think the category will mature toward database-grade semantics, not get displaced by Postgres + pgvector + assembled primitives. HydraDB is one of the systems making that bet credibly today.
Agent memory is a database problem
The renewal agent in the opening didn't fail because it was a bad agent. It read what the infrastructure handed it. The same is true of every other failure here: stale reads, dropped writes, lost audit trails, retroactive corrections with no replay, multi-record incoherence, missing provenance. Database problems with database fixes.
The compute layer is stateless. The model reasons. The infrastructure underneath has to give it consistent snapshots, durable writes, conflict detection, multi-record consistency, bitemporal queries, retention controls, and provenance. Most of the pieces exist somewhere. They don't ship together as one system that an agent team can adopt without months of integration work, which is why identifying the best database for AI agents requires evaluating infrastructure specifically built for stateful workloads.
The question for engineering leaders building stateful agents: pay the assembly cost on Postgres and a stack of glue, or pay a vendor to ship the assembly. Both are defensible answers. What isn't defensible is pretending the problem isn't a database problem.


